
ZooKeeper
ZooKeeper是一个分布式协调服务。
分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的后果。
分布式协调技术的核心就是分布式锁。ZooKeeper适用于读多写少的场景。
分布式锁
分布式锁应具备的条件:
- 一个方法在同一时间只能被一个机器(进程)的一个线程执行
- 高可用、高性能的获取锁和释放锁
- 具备可重入特性
- 防止锁失效机制,防止死锁
- 非阻塞特性,没拿到锁直接返回获取锁失败
常见分布式锁的实现:
- Memecached:利用
add命令,此命令为原子操作,只有在key不存在时,才能add成功,成功了即表示获取到了锁。 - Redis:利用
setnx指令,此命令同样为原子操作,只有在key不存在时,才能set成功,成功了即表示获取到了锁。 - ZooKeeper:利用ZooKeeper的顺序临时结点来实现分布式锁和等待队列,ZooKeeper的设计初衷就是分布式锁服务。
分布式锁的特性
分布式锁有三个重要特性:加锁、解锁、锁超时。下面以Redis实现分布式锁为例,解释分布式锁应用的整个过程。
加锁
当前线程尝试通过setnx key value指令设置一条数据,键为key,值为value。如果设置成功,则表示获取到了锁,如果设置失败,则表示其他线程(可能是不同进程中的线程)已经获取到了锁,当前线程就不能继续操作key了。
key其实就是用来表示分布式系统中的临界资源,需要进行同步控制的资源表示。
value可以是任意值。
解锁
当某个线程操作访问临界资源结束后,就可以释放锁了,在Redis中就是可以通过del key指令来实现,删除了key相关数据,其他线程在加锁时由于key不存在就可以成功加锁。
锁超时
如果某个线程获取到锁后,服务器突然宕机,导致线程没有将key删除(也就是del指令没有执行),那么就会导致其他线程一直无法获取锁。所以我们需要为分布式锁设置一个超时时间(expire指令),在Redis中其实就是为key设置存活时间,当过了存活实现,key就会被自动删除。也就表示释放了锁。
存在的问题
上述过程仍然存在许多问题,如下。
1. 原子操作
当我们没有锁超时机制时,流程为:
- setnx加锁
- del解锁
存在的问题是,当某个线程获取到了锁之后,服务器突然宕机,无法释放锁。所以我们引入锁超时机制。
当我们引入了锁超时机制时,流程为:
- setnx加锁,expire设置超时时间
- del解锁,或超时时间到达,自动del解锁
存在的问题是,当某个线程执行到setnx并成功后,服务器突然宕机,那么expire就没有执行,同样会出现无法释放锁的情况。
上述的问题其实就是操作原子性的问题,setnx、expire、del都是原子操作,当我们加锁时,既需要执行setnx,又需要执行expire,就会导致加锁过程不是一个原子操作,就无法保证能够正常释放锁。
解决方案:执行setnx时同时指定超时时间,即setnx key value expire指令。
2. 误解锁
线程A获取到了锁,并设置了超时时间,但由于某些原因,对数据的操作在锁超时时间内没有完成,而由于key的存活时间到了,Redis将key删除,也就是释放了锁。这时线程B尝试获取锁,并成功,开始对数据进行操作,此时线程A对数据的操作完成,手动del释放锁,而此时del的是线程B获取的锁,也就是线程B的锁被线程A误解锁了,进而其他线程又可以加锁了,又可能产生同样的问题。
解决方案:释放锁时判断是否是自己加的锁。在加锁时,将value指定为当前线程id(加锁时生成的UUID),解锁时判断value是否等于当前线程id(加锁时生成的UUID),如果是则执行del指令,否则不做任何操作。
3. 处理完成前锁释放
回到第2个问题,线程A获取到了锁,但由于某些原因,对数据的操作在锁超时时间内没有完成,进而导致Redis自动将锁释放,这会导致线程A对数据的操作和其他线程产生冲突,这是不允许的。
解决方案:在对数据处理没有完成时,不允许释放锁。具体的做法是,为数据处理线程增加一个守护线程,当锁超时时间临近时,守护线程判断数据是否处理完成,如果没有处理完成,就为key加长超时时间(续命),反复如此,总有一次守护线程进行判断时数据已经处理完成。数据处理完成后守护线程释放锁。
ZooKeeper 的数据模型
ZooKeeper的数据模型类似于数据结构中的树,也很像文件系统。
ZooKeeper的数据模型基于节点,称为Znode。不同于树的节点的是,Znode的引用方式通过路径引用,类似于文件系统。数据都存储在内存中。
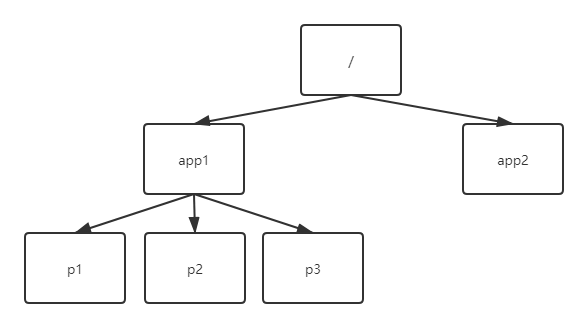
例如:如果需要访问p1,则通过路径/app1/p1访问。路径也称为命名空间。
Znode不是为了存储大量数据而设计的,Znode只存储少量状态和配置信息。
ZooKeeper 的基本操作
- create : 创建节点
- delete : 删除节点
- exists : 测试节点是否存在
- get data : 读取节点数据
- set data : 写入节点数据
- get children : 返回节点的孩子节点列表
- sync : 等待数据传播
ZooKeeper Watch
ZooKeeper通过Watch实现事件通知,Watch可以理解为客户端注册在Znode上的事件监听器,当Znode发生改变时,客户端就会收到对应的通知(观察者模式)。ZooKeeper通过hash结构存储Watch Table,key为节点路径,value为watcher列表。
watcher就是监听节点的客户端。
ZooKeeper 的一致性
ZooKeeper身为分布式系统中的协调服务,如果自身宕机就会产生单点故障,于是ZooKeeper维护了一个集群。
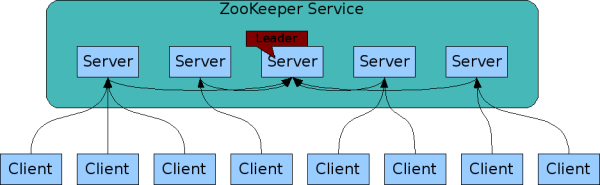
ZooKeeper 集群为一主多从的结构。
在更新数据时,首先更新到主节点(这里的节点是指服务器,不是 Znode),再同步到从节点。
在读取数据时,直接读取任意从节点。
为了保证主从节点的数据一致性,Zookeeper 采用了 ZAB 协议。
ZAB
ZAB 全称 Zookeeper Atomic Broadcast,有效解决了 Zookeeper 集群崩溃恢复,以及主从同步数据的问题。
ZAB 协议定义的三种节点状态:
- Looking:选举状态
- Leading:主节点所处状态
- Following:从节点所处状态
ZXID:节点本地的最新事务编号,包含 epoch 和计数两部分。为单调自增的。
epoch:当前集群所处的年代或者周期,每个 leader 就像皇帝,都有自己的年号,所以每次改朝换代, leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。
当服务启动或者在Leader崩溃后, 集群会进行崩溃恢复,ZAB协议分为4个阶段:
-
Leader Election(选举阶段——选出准Leader)
此时集群中的节点都处于 Looking 状态。它们会各自向其他节点发起投票,投票当中包含自己的服务器 ID 和最新事务ID(ZXID)。
节点会用自身的 ZXID 和从其他节点接收到的 ZXID 做比较,如果发现别人的 ZXID 比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的 ZXID 所属节点。
每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为
准 Leader,状态变为 Leading。其他节点的状态变为 Following。 -
Discovery(发现阶段)
为了防止某些意外情况,比如因网络原因在上一阶段产生多个 Leader 的情况。
所以这一阶段,Leader 接收所有 Follower 发来各自的最新 epoch 值。Leader 从中选出最大的 epoch,基于此值加 1,生成新的 epoch 分发给各个 Follower。(相当于建立新的朝代,确定新的年号)
各个 Follower 收到全新的 epoch 后,返回 ACK 给 Leader,带上各自最大的 ZXID 和历史事务日志。Leader 选出最大的 ZXID,并更新自身历史事务日志。
-
Synchronization(同步阶段——同步follower副本)
把 Leader 刚才收集得到的最新历史事务日志,同步给集群中所有的 Follower。只有当半数 Follower 同步成功,这个准 Leader 才能成为正式的 Leader。
-
Broadcast(广播阶段——Leader消息广播)
到这一阶段,Zookeeper 集群才能正式对外提供事务服务,并且 Leader 可以进行消息广播。
Zookeeper 常规情况下更新数据的时候,由 Leader 广播到所有的 Follower。具体过程如下:
- 客户端发出写入数据请求给任意 Follower。
- Follower 把写入数据请求转发给 Leader。
- Leader 采用二阶段提交方式,先发送 Propose 广播给 Follower。
- Follower 接到 Propose 消息,写入日志成功后,返回 ACK 消息给 Leader。
- Leader 接到半数以上ACK消息,返回成功给客户端,并且广播 Commit 请求给 Follower
ZAB 协议实现的既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性(顺序一致性)。它依靠事务 ID 和版本号,保证了数据的更新和读取是有序的。
